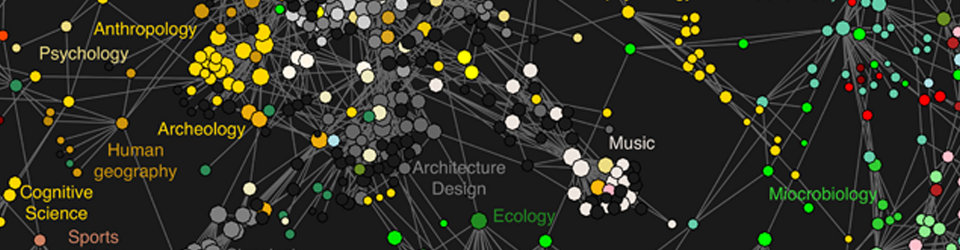
At our weekly Data Science team meeting, a few weeks ago we watched the talk “Everyday Life in a Data Rich World” of Jon Kleinberg, where he lectured about the evolution and the structure of social relations in big scale networks.
[zotpressInText item=”{7KGRGQUT}”]
What caught my attention most in this excellent talk, was a quote used by him right at the beginning:
“The emergence of cyberspace and the World Wide Web is like the discovery of a new continent.”
— Jim Gray, 1998 Turing Award [zotpressInText item=”{J3DKC5SH}”]
This metaphor stimulates my thinking till today and from now and then, new questions arise out of it. Following the metaphor of “the WWW as a new continent”:
Who are the people living on it?
Where do they come from?
Why are they there?
Who does this new continent attract most and who is excluded from living on it?
What are they doing there?
And finally: What are the interests of science in all this?
Right now, I don’t want to get too deep into discussing it, but some things already seem quite obvious:
This is historically the first time scientists get access to such huge amount of data about an global “settlement” activity.
As separated this continent is on one side, as connected it is from another point of view.
It attracts and excludes some people more than others.
The inhabitants of the continent are not representative to the society in general.
But anyway, watch the talk and make your own thoughts (would love to hear about them in the comments section).
On 1st of December the first Computational Social Science Wintersymposium took place at GESIS in Cologne. Here some of my impressions about my second scientific conference.
The topic of the CSS Wintersymposium was “Understanding social systems via computational approaches and new kinds of data”. The day was well visited with about 115 participants – one third from Computer Science, another third from Social Science and the rest from all kinds of disciplines. Funny-wise, I even met two Environmental System Scientists from Osnabrück, something that is not very likely in this relatively new discipline with just a few faculties teaching it.
The conference was introduced by Markus Strohmaier, Head of the Computational Social Science Department here at GESIS and my advisor. During the day several presentations, a Pecha-Kucha and a poster session followed, before it ended in a casual evening in a typical Cologne-style brewery. But let’s take it step by step and get a little bit into the talks which inspired me most (all of them were recorded, as you can see in the playlist below).
Dirk Brockmann: The hidden geometry of complex, network-driven contagion phenomena
Dirk Brockmann from the Research on Complex Systems Department at the Humboldt University Berlin, presented results from his recent work. One of the most impressive work showed was his network analysis about the 2014 Ebola Outbreak [zotpressInText item=”{EAPXQN5N}”], which will stay in my mind for some time. It showed a very useful case, where science delivered desperately needed knowledge to solve real world problems with a huge impact.
Diseases were for me not new, they are a very common usage of Systems Science. In Graz, teachers often used it to show dynamic and complex behaviour of interdependent systems in mathematics, next to the usual predator-prey-models. But mostly it were about formal theoretical thinking or solving hypothetical or long-gone problems, but rarely about an issue that is popping up on my daily news-stream and to which I feel directly related. This experience of connecting my small world of scientific thinking with a global issue was a very inspiring experience and again brought meaning into my thinking about “what do I want to do as a researcher?”. I’m pretty sure, this experience will pop up over and over again to evaluate the relevance of my activities in the future, no matter if in- or outside of science.
Ciro Cattuto: High-resolution social networks from wearable devices
Ciro Cattuto gave a very lively talk about different works of him and his team. As an Open Science enthusiast the SocioPatterns project caught my attention:
…the collaboration supports the development of the SocioPatterns sensing platform, which uses wireless wearable sensors to gather longitudinal data on human mobility and face-to-face proximity in real-world environments. The SocioPatterns team also works on developing tools and techniques to represent, analyze and visualize the collected data.
— SocioPatterns.org
In the study Gender homophily from spatial behavior in a primary school: a sociometric study [zotpressInText item=”{GNGUZC6T}”] this type of data-collection was used to follow children (6–12 years) in a French primary school and measured how long they communicated to each other. The study showed some interesting differences between girls and boys in their development of gender homophily in the early age.
Most of the hardware and software developed for SocioPatterns.org are accessible, but unfortunately they use the Creative Commons BY-NC-SA as license – so not really open, but still the right direction.
Pecha Kucha
Fabian Flöck and me then moderated a Pecha Kucha session with the contributors of the 32 posters. Each talk had exactly 2 minutes time, which we demanded precisely. 😉
The session was really dense and fast, and I think it delivered the main goal quite good: it connected researchers based on their work and interests to being able to get in touch afterwards.
Frank Schweitzer: Modelling emotional agents – Data, Interaction, Simulation
The closing talk, and for me the most interesting one, was held by Frank Schweitzer, a Full Professor for Systems Design at ETH Zurich. He summed up the day and made some clear statements about challenges in the field of Computational Social Science, as the picture below shows.
https://twitter.com/ph_singer/status/539468291522437120/
Copyright: Philipp Singer
I’m thinking a lot about the scientific and socio-cultural dynamics between the Social and Computer Science communities – the problems, the challenges and mostly the many opportunities I see. But more on this sometimes later in an own post.
Resumee
The day was a good balance between heavy input, social interaction and having a nice time. Sounds normal, but often events lack in one of these areas. Too much information can make knowledge processing and memorizing hard and social interactions unease. The positive atmosphere and the good organization made this possible and lead to new connections between researchers from different communities.
For next year I would like to see more discussions about what Computational Social Science is and the different approaches in the intersecting disciplines – getting a little bit out of the comfort zone and creating some constructive friction. A practical part with workshops around questions like “which programming language should I use”, “how to present, share and publish my work best” or “can you show me how to version my code, data and documentation” would be very valuable, especially for early career researchers. Also more discussions about methodological aspects, especially on the link between data design and evaluation would be interesting.
So it is easy to say, the best improvement would be to extend the format and make it 2015 several days. See you hopefully there.
Die geplante Fusion von Springer und Macmillan würde ein Verlagshaus mit € 1,5 Mrd. Umsatz schaffen. Die Mutterkonzerne BC Partners und Holtzbrinck sehen dies als “strategische Transaktion um langfristiges Wachstum zu sichern.” Die ökonomischen Eigenheiten von Oligopolmärkten sind klar, es stellt sich viel mehr die Frage: Was ist das wirkliche Produkt, was ist der Mehrwert der noch generiert wird, welches Problem wird von solchen Konstrukten noch sinnvoll gelöst? Diese Fragen werden umso wichtiger, je stärker auch die Open Access-Veröffentlichungswelt von wenigen zentralen Akteuren dominiert wird.
Der Weg zu Open Science Commons. Das ambitionierte und umfangreiche Projekt “European Grid Infrastructures” erhält grünes Licht von der Europäischen Kommission. Ziel ist vereinfachter Zugang zu gemeinsamen Infrastrukturen, Technologien und wissenschaftlichem Wissen.
Gleichzeitig zwackt die Europäische Kommission Forschungsgelder von Horizon 2020 ab. Umgelenkt werden die Gelder in einen neuen “Investment Plan for Europe“.
Die OANA-Arbeitsgruppen haben ihre Arbeit abgeschlossen und die Ergebnisse liegen vor. Mit dem Auftrag, konkrete Empfehlungen zur Umsetzung von Open Access auszuarbeiten, gingen 5 Arbeitsgruppen an den Start. Die Ergebnisse wurden am 21. Januar in Wien vorgestellt.
Die DFG macht Open Access verbindlich. Für das neue Förderprogramm “Infrastruktur für elektronische Publikationen und digitale Wissenschaftskommunikation” gilt, dass die “in den Projekten erstellten Inhalte und alle aus Projekten resultierende Publikationen […] grundsätzlich über das Internet für alle Nutzer und Nutzerinnen weltweit frei verfügbar” sind.
Transparenz öffentlicher Institutionen muss in der Schweiz per Crowdfunding hergestellt werden. Das Projekt von Christian Gutknecht soll Akteneinsicht in die Finanzlage der Hochschulbibliotheken herstellen.
Investigative, offene Datensätze für die brisanten Fragen. Eine Reihe von Projekten sammelt Informationen zu globalen Unternehmens- und Politikvernetzungen (LittleSis), Konzernen (opencorporates), oder Ölverträgen (OpenOil).
Open Data leichter erkennen. In Österreich startet das Projekt “Open Data Inside“. Mit einem Abzeichen wird die Nutzung von Open Data erkennbar gemacht. Ziel ist, den wirtschaftlichen Mehrwert und Nutzen für die Öffentlichkeit sichtbar zu machen und zu fördern.
Mit Fragen und Antworten Open Science besser erklären. Auf der Fragen-Antworten-Platform stackexchange ist der Vorschlag einer Subseite zu “Open Science” nun in die “Commitment”-Phase eingetreten. Es geht jetzt darum ausreichend Unterstützer*innen zu finden um diese zu starten.
Offen und gleichzeitig übersichtlich. SPARC Europe hat eine Visualisierungshilfe veröffentlich mit der Offenheit der eigenen Forschung und Lehrinhalte dargestellt werden kann. Das Netzdiagramm deckt Aspekte wie Policies, Repositorien oder Verbreitung und Archivierung ab.
Ein Blick nach Vorne
Konferenz und Unkonferenz zu Science 2.0. Die zweite International Science 2.0 Konferenz findet am 25. und 26. März in Hamburg statt. Diskutiert wird im Kontext etablierter Themen rund um Citizen Science, Open Access, Big Data und (Alt-)Metrics. Besprochen werden auch die Ergebnisse der Konsultationen zu “Science 2.0: Science in Transition” und am Vortag gibt es ein Barcamp.
Am 21. Februar schwappt eine Welle von Open Data einmal rund um die Welt. Der globale Open Data Day bietet eine gute Gelegenheit sich international zusammenzusetzen, den Nutzen von Open Data sichtbar zu machen und neue Ideen zu entwickeln.
Citizen Science wird immer mehr zum Thema in Österreich. Die Österreichische Citizen Science Konferenz am 26. Februar soll dazu die wichtigsten Akteur*innen vernetzen und eine Plattform bieten um sich kennenzulernen und Informationen auszutauschen.
Der Call for Papers der Wikimania 2015 in Mexiko City ist offen. Bis 28. Februar können noch Beiträge zu den verschiedenen Tracks (u.a. WikiCulture & Community, Legal & Free Culture, GLAM & Outreach) eingereicht werden. Wer sich die weite Anreise nicht leisten kann, es gibt auch ein Scholarship Programm.
Mozilla will Fähigkeitslücken bei Open Science schließen. Dafür wurde ein Förderprogramm initiiert, mit dem Ziel, Kompetenzen für kollaborative, effiziente, und reproduzierbare Wissenschaft einer breiteren Masse zu vermitteln. Dazu gehören auch Trainingsprogramme für Open Science und datenintensive Forschung.
Open Science 31C3. Vernetzung und Austausch gab es im Workshop der Open Science AG von Open Knowledge auf dem Chaos Communication Congress. Dabei wurden viele Facetten angesprochen, und die Einbettung in andere gesellschaftliche Prozesse diskutiert.
Die Dateiendung als vorletzte Hürde. Proprietäre Formate stehen einer einfachen Nutzung und Veröffentlichung im Weg, und sind dennoch bevorzugte Wahl großer Publisher.
Im Rahmen des deutschen Wissenschaftsjahres “Digitale Gesellschaft” fand ein Webinar zum Thema “Knowledge Sharing in Science” statt. Die Vorträge und die Diskussion mit Alexander Gerber, Muthu Madhan und Peter Kraker gibt es (nach einer Registrierung beim Alumniportal) zum Nachsehen.
Indien macht einen großen Schritt Richtung Open Access. Die zwei größten Forschungsförderer verlangen die Hinterlegung in öffentlichen Repositorien, inklusive Metadaten und ergänzendem Material. Während Daten noch nicht explizit verlangt werden, ist man sich dieses Trends bewusst. Interessant ist auch die Rückwirksamkeit der Policy für die Jahre 2012 und 2013.
Open (Research) Data sind die nächste Stufe der Öffnung. Besonders im englischsprachigen Raum wird Open Access auch für alle digitalen Ergebnisse zunehmend verpflichtend. Das kommt Plattformen wie figshare natürlich sehr gelegen, ist aber auch für Projekte wie e-infrastructures relevant.
Qualität und Bedeutung sind nicht das Gleiche. Eine Studie über Peer Review ergab, dass zwar schlechte Einreichungen abgelehnt wurden, gute aber auch – welche sich im Nachhinein als wegweisende Artikel erwiesen. Nicht nur wurde eine große Zahl an Manuskripten ohne jegliche Peer Review zurückgeschickt, auch 12 der 14 meist zitierten erlitten dieses Schicksal.
Ein Blick nach Vorne
Die i-KNOW wird 2015 von 21.-23.10. in Graz stattfinden. Im vor kurzem veröffentlichten Call for Papers findet sich wieder ein eigener Track zu Science 2.0 und Open Science.
Die Deutsche Forschungsgemeinschaft (DFG) empfiehlt offene Lizenzen. In ihrem Appell werden Creative-Commons-Lizenzen als rechtssichere, anpassbare und standardisierte Mittel angesehen, um Textpublikationen, Daten und Software umfassend nutzbar zu machen.
Das CERN beschleunigt nicht nur Teilchen, sondern auch Open Science. Das neue Open Data Portal bietet sowohl Datensätze für Übungszwecke, als auch Daten inklusive Software für eigene Forschungen.
Bereits jedeR zweite ForscherIn macht Forschungsdaten öffentlich zugänglich. Anreize zum Teilen von Daten sind zum einen bessere Sichtbarkeit und höherer Impact, aber auch gestiegene Anforderungen von Journals. Die geringe Nutzung von Datenrepositorien (6-26%) schränkt allerdings die Auffindbarkeit ein. Die von Wiley unter 90.000 ForscherInnen durchgeführte Umfrage schlüsselt auch nach Disziplinen und Ländern auf.
Wieviel kostet die Umsetzung von Open Access? Für das UK gibt es nun konkrete Zahlen. Die Umsetzungskosten von Open Access betragen hier 11,7 mio € und zusätzlich 14 mio € für Publikationsgebühren. Ein von London Higher und SPARC Europe beauftragter Bericht beziffert auch den zeitlichen Mehraufwand: zwischen 45 Minuten (Grüner Weg) und 2 Stunden (Goldener Weg).
1.732.556 € für 1.432 Open Access-Artikel. Das ist die Summe, die von 7 Institutionen für Publikationsgebühren in Deutschland aufgewendet wurde. Der Datensatz selbst ist auf github zu finden, und wird hoffentlich noch wachsen.
Die Niederlande kündigen Elsevier… Da der Vorschlag von Elsevier nicht den Open Access-Anforderungen der niederländischen Universitäten entspricht, sind die Verhandlungen vorerst auf Eis gelegt. … und behalten Springer. Eine Einigung ergab sich, weil Springer das Ziel von 60% Open Access bis 2019 und 100% Open Access bis 2025 mittragen will.
Peer Review und alternative Metriken müssen sich sinnvoll ergänzen. Peer Review messe Konformität zu disziplinären Erwartungen und Bibliometriken messen wie sichtbar ein Werk am Horizont anderer WissenschaftlerInnen auftaucht, argumentiert Derek Sayer. Bei der Forschungsevaluation solle der Fokus besser auf Eigenschaften der Forschungsumgebung gerichtet werden: Bibliotheks- und Laborressourcen, Forschungseinkommen, Redakteurstätigkeiten, Beteiligung an Konferenzen, Anzahl an PhD-StudentInnen oder Seminar- und Vortragstätigkeiten.
Wenigstens sind die Wege kurz. Ein weiterer möglicher Fall von Selbst-Review innerhalb von Thomson Reuters ScholarOne zeigt die Probleme der aktuellen Peer Review-Verfahren auf. Eine Reihe von Einzelfällen deutet auf ein systematisches Problem hin.
Die Ludwig Boltzmann Gesellschaft startet eine Crowdsourcing-Plattform für Forschungsfragen. Im Rahmen des Projekts sollen Forschungsfragen zu psychischen Erkrankungen formuliert werden. 2016 folgt ein Ausbildungsprogramm, das Forschern “Open-Innovation”-Methoden nahebringt.
Bürgerwissenschaften erleben einen zweiten Frühling. Citizen Science muss nicht immer große Mengen an kleinen Beiträgen bedeuten, es kann auch mit kleinen Mengen an stark involvierten Beiträgen funktionieren. Benedikt Fechter beschreibt das Potential von Citizen Science, und warum man in den freiwilligen BürgerInnen mehr als nur “Helferbienen” sehen sollte. In einem Wissenschaftsdossier der APA mit Schwerpunkt zu Citizen Science wird die begriffliche Vielfalt zusammengefasst.
Bei der Umsetzung von Open Science spielt der disziplinäre Kontext eine wichtige Rolle. Daher ist es wichtig, die einzelnen Communities in den Diskurs mit einzubeziehen, argumentiert Peter Kraker auf dem LSE Impact Blog.
Wie schaut dieser Kontext in den Geisteswissenschaften aus? Martin Paul Eve gibt mit seinem Buch Open Access and the Humanities einen vielseitigen Einblick in die entscheidenden Faktoren wissenschaftlicher Kommunikation in den Geisteswissenschaften und beschreibt Open Access Ansätze, die diese besser berücksichtigen.
Und wir bewegen uns doch. Die erste OpenCon (Zusammenfassung) fand vom 15.-17. November in Washington, DC, statt. Die meisten Vorträge und Workshops sind nachträglich abrufbar, sowie eine Reihe interessanter Podcasts. Weitere Ressourcen werden auf der Konferenzwebsite zur Verfügung gestellt.
Die Europäische Kommission sichtet die Ergebnisse der Befragung zu Science 2.0. In vier Workshops haben VertreterInnen der Kommission mit verschiedenen Stakeholdern über wichtige Kernthemen dieses Wandels diskutiert. Der Validierungsprozess kann auf scienceintransition.eu verfolgt werden.
Die zweite Runde der Panton Fellowships endet. Zeit, um die Experimente und Erkundungen der drei Fellows in den Bereichen Open Data und Open Science Revue passieren zu lassen.
Ein Blick nach Vorne
Eine Open Science Erhebung soll internationale Vergleichbarkeit herstellen. Die Initiative von Open Knowledge beginnt gerade mit der Ausarbeitung von Fragen.
Unsere Projekte
Wie lassen sich Zugänge zu Open Science vereinfachen? Das Projekt Open Science @ Uni Graz sucht Vorschläge und Input zum Thema Diversität.